实时渲染笔记-Global Illumination

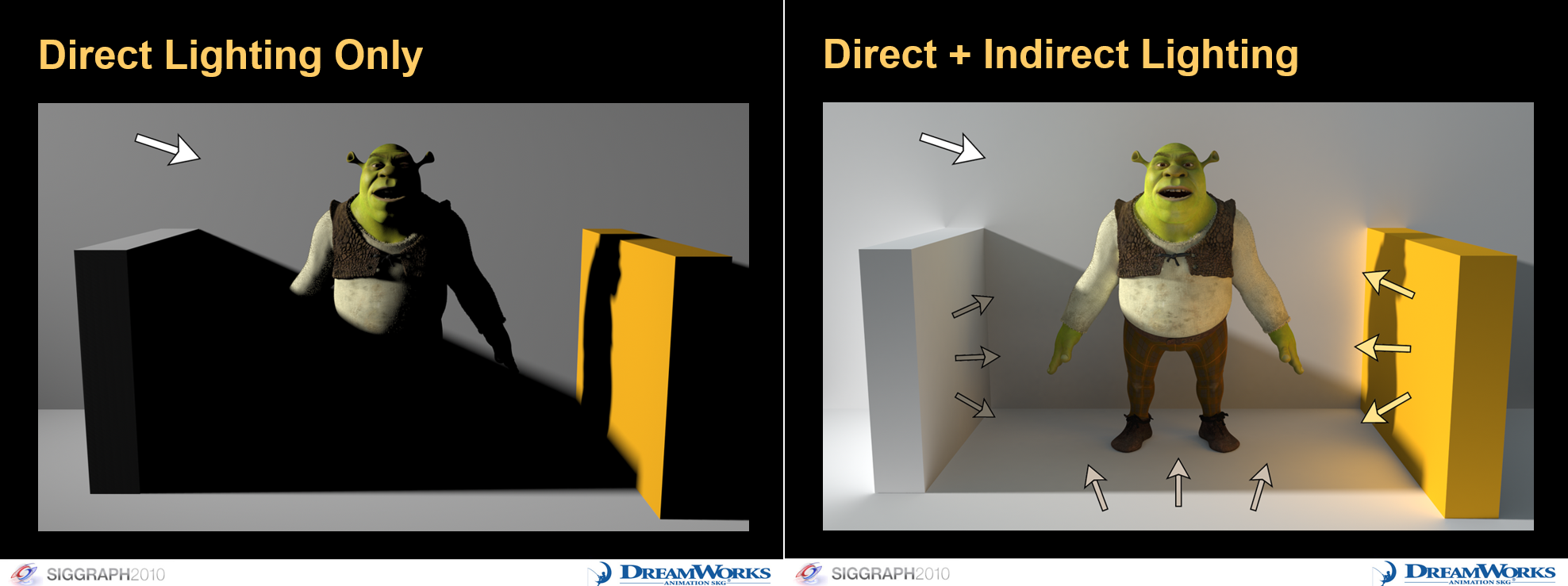
全局光照对于渲染真实的场景起到至关重要的作用。通常情况下,整个场景被照亮是一个非常复杂的过程,一个shading point可能会受到直接光照、间接光照、散射、焦散、阴影等等的影响,如上图所示。所以没有全局光照只有直接光照会导致渲染的结果不真实,最直观的效果就是阴影区域非常黑,而有了间接光照,阴影区域就会有一个合理的亮度。
 # Reflective Shadow Maps (RSM)
# Reflective Shadow Maps (RSM)
Reflective Shadow Map (RSM) 从名称上也可以看出来,这种方法的思路和Shadow Map是一致的,区别是Shadow Map只记录从光源出渲染的深度,而RSM还会存储包括深度、世界坐标、法线、光照能量等信息

它的基本思想是,从光源视角出发,我们可以得到所有可以被光源照亮的区域,这些区域就可以当作是次级光的发出光源。在Shadow Map上的每一个像素可以视作是一小片间接光的光源patch,我们知道光入射的方向,但是我们不知道光出射的方向。因此,RSM作出了一个假设,假设这些patch的surface都是diffuse的,因此出射光是朝着半球面各个方向发散的。
现在我们需要知道每一片间接光光源patch对shading point的贡献。回顾渲染方程,可以通过换元将单位立体角上的积分转化为对光源面积的积分,下面是表示p点照亮q点反射的渲染方程。 \[ \begin{align*} L_o(q, \omega_o) &= \int_{\Omega_\text{patch}} L_i(q, \omega_i) V(q, \omega_i) f_r(q, \omega_i, \omega_o) \cos \theta_i \, d\omega_{i}\\ &= \int_{A_\text{patch}} L_i(p \to q) V(q, \omega_i) f_r(q, p \to q, \omega_o) \frac{\cos \theta_p \cos \theta_q}{\|q - p\|^2} \, dA \end{align*} \]
由于我们假设次级光源表面是diffuse的,所以有 \[ f_{r}(p)=\frac{\rho}{\pi} \] Shading point接收到的radiance就是这一个patch反射出的光强,这里从光源到次级光源的radiance可以写作flux和面积的比值,这样的好处是面积可以和积分中的面积约掉,这样子在存储的时候只需要存储一个flux就可以了,而不用考虑面积。 \[ L_{i}(p)=f_{r}(p)\cdot E(l \rightarrow p)=f_{r} \cdot \frac{\Phi}{\mathrm{d}A} \] 存储了次级光源处的flux,我们就可以在渲染q点的时候利用存储的flux通过以下公式计算出p点对q点贡献的irradiance大小。这里忽略了从p点到q点的visibility的计算,因为如果每一个光线都计算的话计算量太大,很难算。所以RSM直接假设所有的次级光源对于shading point都是可见的。
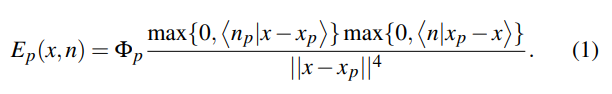
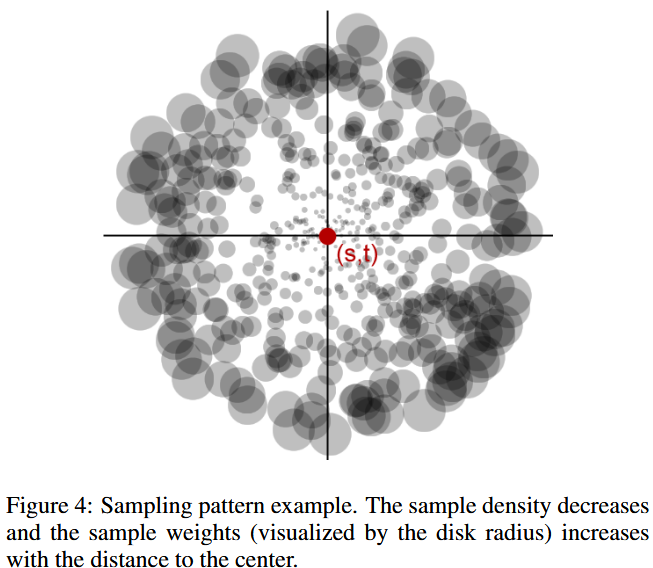
当然,在实际实现过程中,我们不可能把shadow map上所有的像素都进行计算,所以我们需要进行采样。总体上看,离shading point更近的次级光源对于shading point会更大。这里RSM再次作出假设,根据shading point在shadow map上的位置和次级光源在像素上的位置的距离进行不同密度的采样,距离近的采样密度大,远的采样密度小。对于采样的结果,RSM引入了权重,权重同样通过距离决定,越近权重越小,越远权重越大。
RSM好处在于实现非常简单,完全按照Shadow Map的一套流程,但是性能有待提高,因为对于每一个光源都需要生成相应的RSM,而且由于存在很多假设,并且只考虑了一次反射的间接光,所以效果肯定是局限的。
Light Propagation Volumes (LPV)
在全局光照中,我们核心要解决的问题是在shading point上获得从任意一个方向上接收到的radiance大小。通常情况下,我们都会采用一个基本假设,也就是radiance在传播过程中大小是不会改变的。LPV从名称上看,采用了Volume的方式,让光线在volume中进行传播。具体实现中,分为以下步骤
- 生成直接光照的场景表示
- 第一步采用了Reflective Shadow Map的办法,生成一个虚拟次级光源的集合,同样的,将次级光源的表面假设为diffuse材质。
- 次级虚拟光源在场景体素中的注入
- 将整个场景划分为三维网格
- 对于每一个格点,找到其中所有的虚拟光源,将虚拟光源的有向radiance贡献相加
- 对于有向radiance,可以使用Spherical Harmonics进行压缩,常用的做法是映射到二阶SH上
- 体素中的radiance传播
- 对于每一个格点,计算上下左右前后的六个格点中光源的对该格点的贡献,并重新映射到SH上
- 迭代若干次,使得LPV达到稳定的状态(这有点类似流体中的格点法)
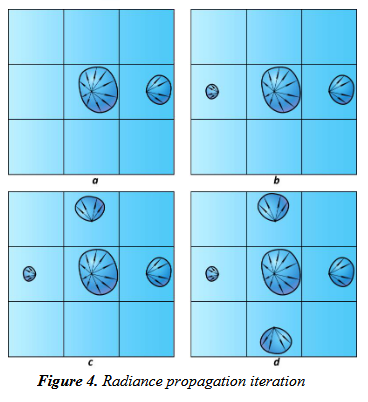
- 使用最终的light propagation volume进行场景渲染
- 在最后渲染时,对于每一个shading point,找到它所在的格点,利用格点中存储的radiance进行渲染
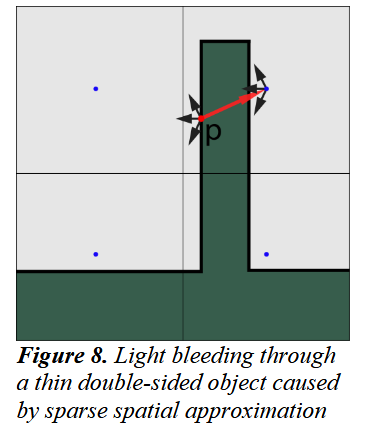
这样的方法在最后渲染时存在一个问题,如上图中,如果三维网格的划分过于稀疏,就会存在虽然一个次级光源本不该照亮一个被遮挡的shading point,但是由于他们在同一个网格之中,实际计算会考虑这个次级光源的贡献的。因此,就会有下面的结果的出现

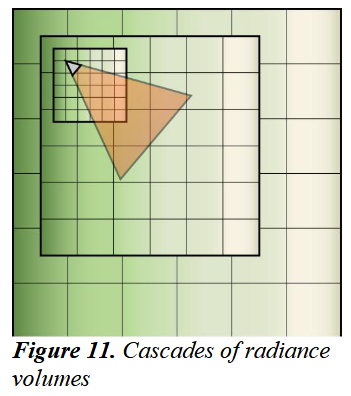
在工业界的具体实现中,可能会存在一些自适应网格的方法,使用不规则的网格大小适应不同区域内的物体大小,带来的损失就是需要较为复杂的计算。更常见的做法时Cascaded的LPV,采用层级网格对不同距离的物体用不同大小的网格。
Voxel Global Illumination (VXGI)
VXGI也是一个2pass的算法,但是区别于Reflective Shadow
Map,VXGI采用了Voxel对radiance信息进行存储。总体上VXGI分为两个步骤 1.
light
pass:从光源视角出发,发出光线,同样的生成次级光源的patch,存储在八叉树的网格结构中
2. camera pass:从摄像机出发,根据shading
point的BRDF采样一个反射的cone,并计算其贡献 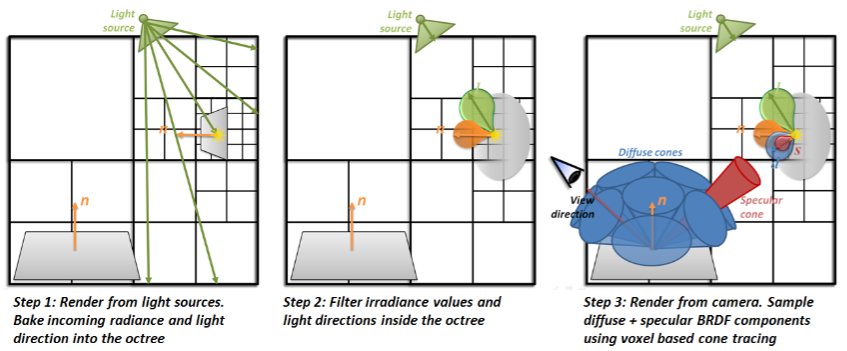
具体的,首先VXGI将整个场景划分为一个层次化结构,使用八叉树进行网格划分。使用层次结构(Hierachical structure)的好处是我们可以获得一个类似mipmap的结构,在最后的渲染中可以使用更高级的节点进行估算。在light pass中,首先从光源出发,我们可以将每个光源patch的radiance计算出来,存储在八叉树的叶子节点中。为了实现mipmap的效果,需要继续进行filtering,逐层的更新父级节点的radiance。具体细节参见paper。
有了存储的radiance之后,在cone tracing的时候就可以进行加速。最直观的思路是找到cone内所有相交的voxel,将所有的贡献相加,这显然是不显示的。VXGI提出的方法类似于ray marching,从shading point出发逐级步进,在之前存储的层次化结构上逐级查询,通过插值得到贡献的radiance大小。
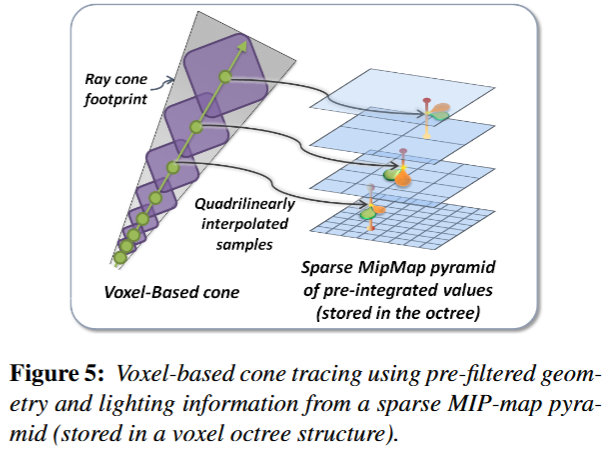
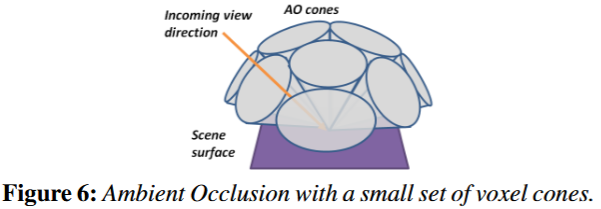
对于glossy材质的物体,只需要采样一个cone,而对于diffuse的物体,理论上我们需要计算整个半球面上所有的次级光源的贡献。VXGI提出我们可以近似的用多个cone去近似的覆盖整个半球面(8个)
Screen Space
RSM、LPV、VXGI都是直接利用三维空间中的信息计算Global Illumination,这些方法基本上都有一个缺陷,就是性能消耗比较大。Screen Space的方法性能相比于三维空间会更好,这类方法的基本思想是从screen space上的直接光照信息通过后期处理计算出间接光照。 ## Screen Space Ambient Occulusion (SSAO)
环境光遮蔽(AO)指的是环境中的间接光由于物体的几何关系产生遮挡产生的视觉效果,AO往往能带来更真实的视觉效果。SSAO是一种在屏幕空间中对全局光照估计的一种方法。
SSAO做了以下假设 1. 任意一点的间接光照的强度都是常数(类似于Phong光照模型中的ambient项) 2. 我们只需要考虑在每个shading point在各个方向上的可见性 3. 同样的,假定表面都是diffuse材质
在理论上为什么我们只需要考虑shading point的visibility呢?首先,从rendering equation出发 \[ L_{o}(p. \omega_{o})=\int_{\Omega+}L_{i}(p,\omega_{i})f_{r}(p,\omega_{i},\omega_{o})V(p, \omega_{i})\cos{\theta_{i}}\mathrm{d}\omega_{i} \] 利用结论 \[ \int_{\Omega}f(x)g(x)\mathrm{d}x\approx\frac{\int_{\Omega_{G}}f(x)\mathrm{d}x}{\int_{\Omega_{G}}\mathrm{d}x} \cdot \int_{\Omega}g(x)\mathrm{d}x \] 分离visibility项
\[ L_{o}^{\text{indir}}(p, \omega_{o}) \approx \frac{\int_{\Omega_{+}}V(p, \omega_{i}) \cos{\theta_{i}}\mathrm{d}\omega_{i}}{\int_{\Omega_{+}}\cos{\theta_{i}}\mathrm{d}\omega_{i}} \cdot \int_{\Omega_{+}}L_{i}(p, \omega_{i})f_{r}(p, \omega_{i}, \omega_{o})\cos{\theta_{i}}\mathrm{d}\omega_{i} \] 这里利用了\(\mathrm{d}x_\perp=\cos{\theta_{i}}\mathrm{d}\omega_{i}\)的结论,从半球面上的积分转化到了平面上的积分
其中第一项经过化简之后就是所有方向上的visibility cos加权平均 \[ k_{A}=\frac{\int_{\Omega_{+}}V(p, \omega_{i}) \cos{\theta_{i}}\mathrm{d}\omega_{i}}{\pi} \] 第二项是间接光照,由于SSAO作出的假设,这一项就是常数 \[ L_{i}^{\text{indir}}(p) \cdot \frac{\rho}{\pi} \cdot \pi=L_{i}^{\text{indir}}(p) \cdot \rho \] 所以现在的问题就是我们应该如何计算shading point的遮罩\(k_{A}(p)\)。
SSAO利用屏幕空间中存储的depth
buffer来解决这个问题。我们需要计算shading
point在各个方向上的visibility的均值,很自然的我们就可以进行采样对这个值进行估算,具体的我们会在shading
point的一定半径的球面或者半球面进行采样。我们可以分成shading
point上有法线和没有法线两种情况 - SSAO(有法线) - 在shading
point一定半径范围内的球内进行采样,采样点投影到camera,得到采样点的深度
- 采样点的深度和屏幕空间记录的深度作对比,小于screen
space深度即为可见,大于screen space深度即为不可见 -
因为没有法线信息,所以只能在整个球里进行采样。当过半的采样点在物体内部,说明有AO,否则就不需要AO
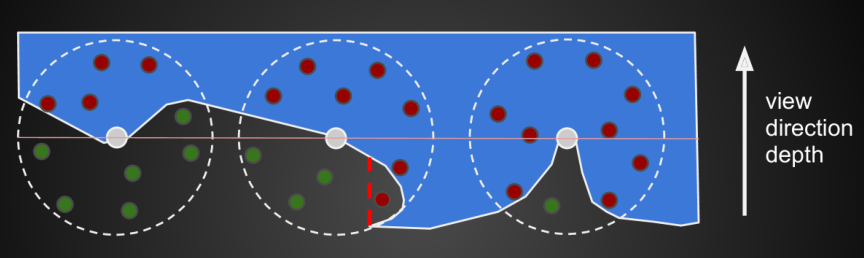 - 问题:会出现false occulusion的问题
- 问题:会出现false occulusion的问题  - Horizon based ambient occulusion (HBAO) 有法线信息
- 在法线所在的半球面上进行采样 - 有了法线信息可以加入cosine权重
- Horizon based ambient occulusion (HBAO) 有法线信息
- 在法线所在的半球面上进行采样 - 有了法线信息可以加入cosine权重 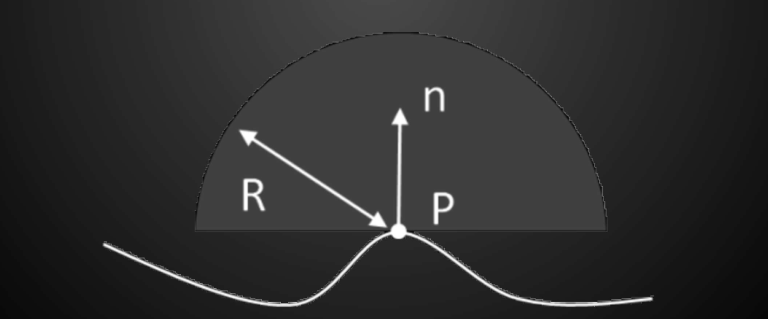 ## Screen Space Directional Occlusion (SSDO)
## Screen Space Directional Occlusion (SSDO)
SSAO中假设所有的indirect illumination是相同的,但实际上在screen space上我们也有可以直接利用的间接光照信息,也就是从camera视角下已经渲染好的图像。SSDO就是在此基础上对SSAO的改进。SSDO的基本思想是,从shading point出发,随机射出光线,击中障碍物,说明是间接光照,未击中则是直接光照。
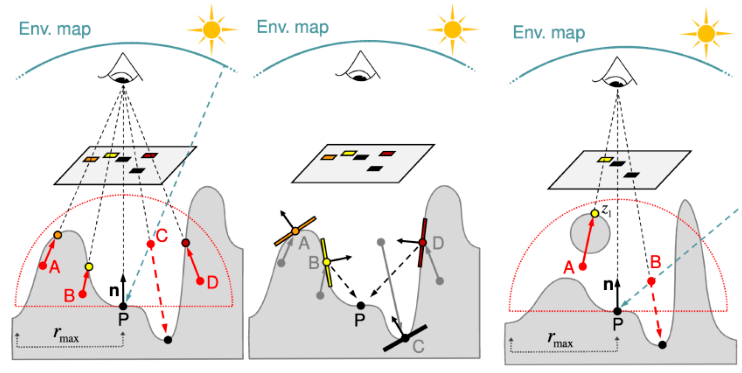
类似于SSAO,SSDO从shading point所在的半球面上进行采样,从采样点到P点的visibility同样的利用深度进行估计。如果在物体外部没有遮挡,采用环境光贴图的直接光照;如果在物体内部,那么利用从摄像机出发看到的surface patch作为次级光源计算简介光的贡献(具体方法和RSM类似)。当然因为visibility是通过摄像机的visibility近似得到的,所以实际情况下会有不符合的情况(上图右)。
SSDO的问题是,由于采样点的半球范围限制,间接光照只能计算在一定范围内的,无法计算远距离的。这一点和SSAO刚好相反,SSAO假设可见部分可以被远距离的环境光照亮,被遮挡的无法照亮;SSDO则是被遮挡部分会贡献间接光照,远距离无间接光贡献。另一个问题是screen space存在的问题,由于screen space只记录了从摄像机视角看到的信息,会忽略摄像机没有看到的信息,如下图所示,当左侧的表面消失在摄像机视野内时,它在地面的间接光照贡献就会被忽略。

Screen Space Reflection (SSR)
SSR是一种在屏幕空间作的ray tracing,因此不需要三维空间中的mesh信息,而是利用屏幕空间中的法线、深度、图像信息。SSR的基本思路时,对于一个shading point,去trace它的反射光线。这里不需要对shading point的材质作出限制,无论时specular还是glossy的材质,都可以使用path tracing中类似的方法去sample一根光线。

在trace反射光线的过程中,我们需要一个合适的步长,如果步长太大或者步长太小都会导致问题。因此SSR提出了Hierarchical ray trace的方式。这种方法需要使用到Depth Mip-Map (HiZ),和普通Mipmap不同的是HiZ在filtering的時候用的是min pooling而不是平均,这样可以保证如果一个光线没有和一个高层级的节点相交,那它肯定也不会和低层级的节点相交。具体的trace伪代码如下
1 | mip = 0; |
在SSR中,由于我们仍然需要知道次级光源的出射radiance,所以次级光源表面的材质仍然假设是diffuse的。但是SSR很好的解决了shading point和次级光源的可见性问题,因为是严格的进行ray trace得到的结果。